Superskalárne GF104: evolúcia GF100?
Plné jadro GF100 má 4 GPCs (Graphic Processing Clusters) clustre, 6x 64bit pamäťových radičov s 48 ROPs a L2 cache, Host Interface a plánovač s názvom GigaThread Engine, ktorý rozdeľuje prácu vo vnútri jednotlivých GPCs. Každý GPC obsahuje Raster Engine a 4 SMs (Streaming Multiprocessors).

Zmena u GF104 nastala hlavne v štruktúre samotných GPCs. Jeden SM už nemá 32 Cuda jadier ako u GF100, ale po novom 48. Zdvojnásobil sa aj počet SFUs a TMUs. SFU - špeciálna jednotka, ktorá dokáže spracovať transcendentálne inštrukcie, ako napríklad sin(x), cos(x), 1/x, 2x, log2(x). Každá SFU zvláda jednu takúto inštrukciu za takt. Pozitívnou zmenou bol aj nárast počtu textúrovacích jednotiek na jeden GPC cluster. Aj keď má GF104 len polovicu GPCs, disponuje rovnakým počtom textúrovacích jednotiek ako GF100. Okrem iného textúrovacie jednotky už vedia filtrovať s FP16 v plnej rýchlosti, zatiaľ čo GF100 len v polovičnej.
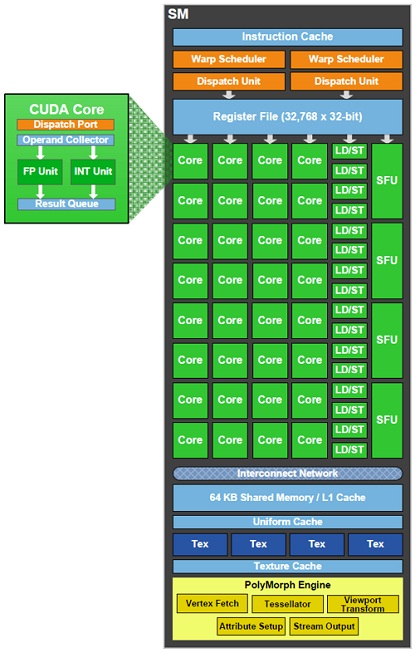
L2 cache kvôli súvislosti s pamäťovými radičmi klesla na veľkosť 512kB pre 256bit verziu, pre 192bit na 384kB (GF100 má pri plnej 384bit zbernici 768kB). S počtom pamäťových radičov úzko súvisí aj počet ROPs. Každej skupine 8ich ROPs pripadá jeden 64bit pamäťový radič. Zvyšok GPCs ostal u GF104 rovnaký. Každý SM má k dispozícii 64kB konfigurovateľnú pamäť, ktorú je možné prideliť 48kB pre L1 cache a 16kB pre zdieľanú pamäť, resp. 16kB pre L1 cache a 48kB pre zdieľanú pamäť. Aj keď jej veľkosť oproti GF100 neklesla, zvýšil sa počet Cuda jednotiek, ktoré sa teraz o ňu delia.
Samozrejmosťou je jeden Polymorph engine na jeden SM. Táto jednotka je zodpovedná za spracovanie geometrických operácií.
Zaujímavou zmenou je využitie jednotlivých blokov SM u GF104. Zatiaľ čo u čipu GF100 je v každom SM:
- 1. blok (16) Cuda jadier
- 2. blok (16) Cuda jadier
- 16 Load/Store jednotiek
- 4 TMU
- 4 SFU
a využitie blokov Cuda jadier, LD/ST jednotiek, a SFUs je zabezpečené pomocou TLP (Thread Level Parallelism) cez jeden warp sheduler a jednu Dispatch jednotku. SM u GF100 môže spracovanie inštrukcií dvoch warpov (1warp = 32threadov) odoslať v jednom cykle akýmkoľvek dvom blokom.
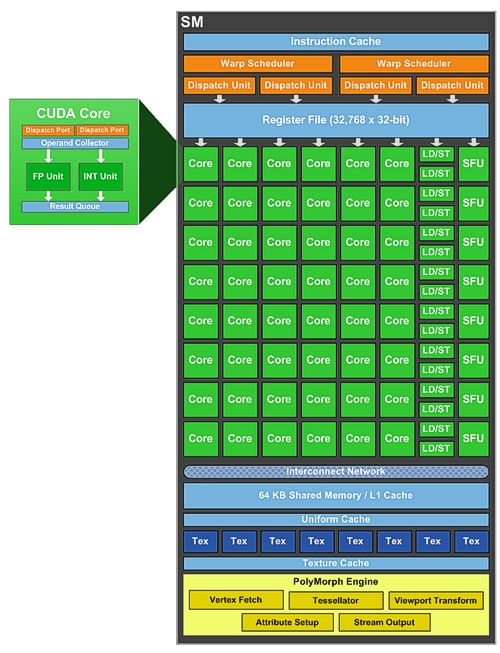
U GF104 je ale situácia iná, má o jeden blok Cuda jadier viac, ale stále rovnaký počet warp shedulerov.
- 1. blok (16) Cuda jadier
- 2. blok (16) Cuda jadier
- 3. blok (16) Cuda jadier
- 16 Load/Store jednotiek
- 8 TMU
- 8 SFU
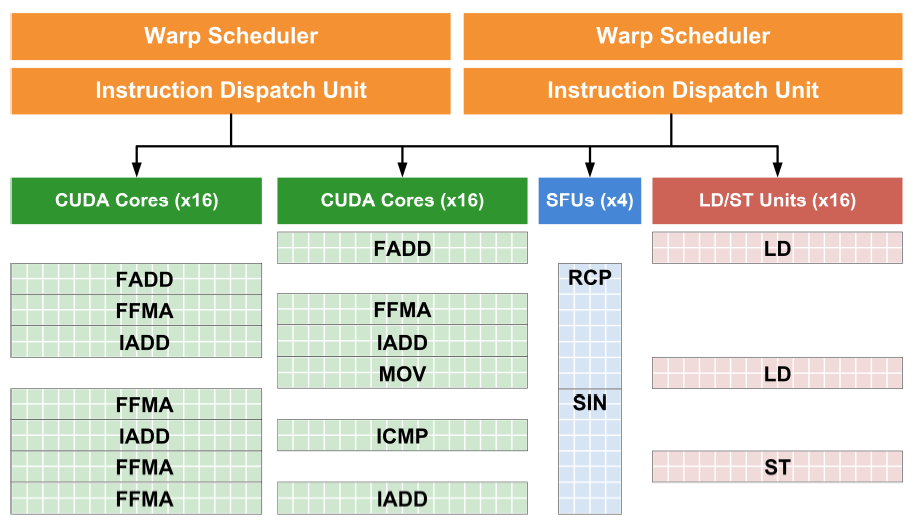
Pri použití TLP by ostal stále jeden blok Cuda jadier nevyužitý. Preto, aby neidlovalo viacero jednotiek, musela nVidia zmeniť spôsob využitia jednotlivých blokov. Ako to dokázala s použitím rovnakého množstva warp shedulerov? "Jednoducho", použitím superskalárnej metódy ILP (Instruction Level Parallelism).
Každý warp sheduler je pripojený u GF104 na 2 dispatch jednotky. V najideálnejšom prípade, ak sú na sebe inštrukcie v threade nezávislé, warp sheduler ich rozdelí pre dva bloky, ktoré ich spracujú paralelne. Takto dokáže odoslať inštrukcie 4 z 5blokov, zatiaľ čo GF100 len 2 zo 4. SM spracováva inštrukcie superskalárne na základe ich analýzy vo warp shedulery. Nevýhodou je ak sú inštrukcie závislé, vtedy warp sheduler odošle inštrukcie len 1 bloku v cykle. Využitie klesne len na 2bloky z 5. Čo je pri spracovaní inštrukcií Cuda jadrami vyťaženie 256 z celkového počtu 384, teda len 66%.
Pre zníženie nákladov a zmenšenie čipu nVidia obmedzila "profi" vlastnosti GF100 v podobe výpočtov s DP, u G104 vie len jedna časť SM (16 zo 48Cuda jadier) FP64. Okrem toho GF104 prišla o podporu ECC, čo je ale u hráčskeho obecenstva nezaujímavé.
adun
yesper
mano8
crux2005
mano8
n0vIc3
Rolko 75
helevole
misog
yesper