Zipfov zákon je známy už dlhšie. Odolával vysvetleniu takmer jedno storočie a stal sa najväčšou záhadou výpočtovej linguistiky. Nedávno médiami prebehla správa, že s jej riešením prišiel Sander Lestrade z Radboud University of Nijmegen. V krátkom rozhovore vysvetľuje svoje riešenie Zipfovho zákona.
Rozhovor so Sanderom Lestradeom o jeho riešení storočnej záhady Zipfovho zákona
1. Môžete v krátkosti opísať Zipfov zákon našim čitateľom?
Sander Lestrade: Zipfov zákon hovorí, že frekvencia slov v texte môže byť popísaná vo vzťahu k jeho frekvenčnej pozícii, že druhé najčastejšie používané slovo je spolovice časté ako prvé (frekvencia prvého slova/2), tretie slovo má tretinovú frekvenciu frekvencie prvého slova (frekvencia prvého/3) atď. Celou cestou dolu až po posledné používané slovo, ktoré sa vyskytne iba raz!
2. Platí Zipfov zákon pre každý jazyk? Ak nie, pre ktoré jazyky neplatí?
Sander Lestrade: Hoci som to sám neskontroloval, jazykovedci tvrdia, že zákon samozrejme platí pre každý jazyk. (Povedal by som, že neplatí pre pindžin jazyky, no tie nemajú vlastnú gramatiku.)
3. Môžete nám vysvetliť Váš objav? Citujúc z tlačovej správy "Ak vynásobíme rozdiely vo význame vnútri slovného druhu (word classes)", s potrebou pre každý slovný druh (word class), nájdete úžasnú Zipfiánsku distribúciu." Môžete to vysvetliť trochu bližšie, čo je rozdiel vo význame, ako to kvantifikujete? Možno príklad pomôže.
Sander Lestrade: Viem si predstaviť, že to takto povedané znie trochu neprehľadne :) Myšlienka je, že slová sa líšia v špecifikácii významu: "auto" je všeobecnejšie než "SUV", ale viac špecifickejšie ako "vozidlo". Môžete to namodelovať v počte (abstraktne numericky) významových dimenzií, pre ktoré je slovo špecifikované. Pre čím menej rozmerov je slovo špecifikované, na tým viac odkazov môže byť v princípe použité (pre čokoľvek je niečím). Ale na to, aby bolo použité úspešne, by slovo malo byť dostatočne špecifické na vybratie jeho odkazov v kontexte (významových odkazov). Možete to simulovať generovaním kontextu s cieľovým odkazom a niekoľkými odputávacími objektmi (number of distractor objects), a potom sa pozrieť, ktoré slová sú dostatočne špecifické na určenie cieľa a náhodne vybrať jedno z nich.
Alebo môžete vypočítať pravdepodobnosť, s ktorými slovami bude použité, berúc do úvahy ich významové špecifikácie. Takto môže byť ukázané, že najčastejšie používané slová majú priemerné špecifikácie (moderate specification), ktoré sa správajú pekne kvadraticky voči frekvencii používania slov v prirodzenom jazyku (kontrolovaním korelácie medzi frekvenciou používania slov s ich pozíciou v slovných taxonomiách akým je WordNet).
Toto je hlavná časť: slová by mali byť čo sa týka významu všeobecné, aby boli zvažované často, ale dostatočne špecifické aby boli používané.
A vo výpočtových modeloch, pravdepodobnosť používania slov môže byť vypočítaná exaktne. Táto sémantická pravdepodobnosť musí byť násobená (doslovne) s potrebou slova v kategórii. Jazyky majú pravidlá, ktoré hovoria ako majú byť slová kombinované. Sloveso potrebuje jednu alebo dve nominálne frázy (frázy s podstatným menom), nominálna fráza sa vo všeobecnosti vyskytuje s členom, atď. To vedie k niekoľkým slovným druhom (ako slovesá, podstatné mená, zámená, predložky), ktoré majú očakávanú frekvenciu používania v jazyku.
Približne, druhy sú používané rovnako často, ale ohromne sa odlišujú veľkosťou (množstvom slov): v Angličtine máme len tri členy, ale desiatky tísíc podstatných mien. Dôsledkom je, že člen je používaný omnoho častejšie ako podstatné meno. Berúc do úvahy čo bolo povedané o význame, slová nie sú používané rovnako často v rámci svojich druhov. Hoci, to záleží na ich významovej špecifikácii.
4 . Dáva nám Vaše vysvetlenie-teória náhľad do toho, prečo sú jazyky postavené práve takýmto spôsobom? Prečo majú Zipfiánsku distribúciu a nie nejakú inú distribúciu?
Sander Lestrade: Berúc do úvahy, že dané slovné druhy (word classes) sa rádovo odlišujú veľkosťou, určitá veľmi hrubá mocninová závislosť je očakávateľná. Otázkou potom je, prečo majú jazyky malé gramatické a veľké lexikálne/slovné druhy (lexical classes). Slovné/lexikálne druhy sú vysvetliteľné ľahko: potrebujeme mnoho slov keď chceme hovoriť o veciach ktoré nás zaujímajú. Prečo vznikli gramatical classes je menej jasné. Podľa mňa, sú náhodným postranným produktom používania jazyka, ktorý sa vyvinul postupom času, nie sú vnútornou časťou jazyka. No nie každý by s tým súhlasil :)
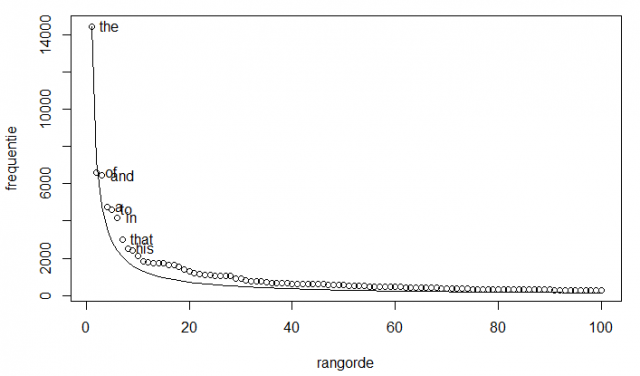
Zipfianské rozdelenie frekvencie (vertikálna Y-ová os) a poradie vo frekvenčnom stĺpci (horizontálna X-ová os), prvých sto slov Melvillového Moby Dicka. Spojitá krivka ukazuje predpoveď Zipfovým zákonom a krúžky zobrazujú skutočnú frekvenciu slov v texte.
lesna.vevericka
asdfasdf