Zmeny v architektúre
Mohlo by sa na prvý pohľad zdať, že Sandy Bridge je len evolúciou predchádzajúcej generácie Nehalem. Ide však v skutočnosti o niečo celkom nové, aj keď stavia na základoch predošlých generácií. Zaujímavosťou je, že sa použili niektoré nápady ešte z éry P4 (Pentium 4) procesorov (NetBurst), no väčšina sa podobá na P6 (Nehalem). V podstate ale takmer každý aspekt jadra bol pozmenený. Všetko v rámci filozofie Intel-u zvyšovať výkon a efektivitu samostatných jadier. Prístup AMD pri tvorbe Bulldozeru je zameraný skôr na celkový, súhrnný výkon procesora.
Zmeny v dizajne sú viditeľné už na začiatku pipeline procesora – pri dekodéroch inštrukcií. Dekodér v podstate ostáva rovnaký ako u Nehalem-u, spracuje 4 inštrukcie za takt a podporuje Micro-Fusion a Macro Fusion techniky, ktoré robia výstupný tok inštrukcií viac vyrovnaný po stránke komplexnosti. Avšak dekódované inštrukcie sa neposúvajú iba do ďalších blokov, ale sa tiež ukladajú do akejsi „L0 cache“ o veľkosti 6kB (pojme asi 1500 micro-ops). Okrem L1 dátovej cache sa teda ukladajú aj výsledky po dekódovaní – tento nápad pochádza z Pentium 4 architektúry. Načo je to dobré? Ak dekodér zistí inštrukcie, ktoré už boli predtým dekódované, neprevedie znova celý proces dekódovania (čo si vyžaduje dosť veľa energie), ale siahne do cache a vytiahne si výsledky odtiaľ. Efektivita by mala byť okolo 80%.
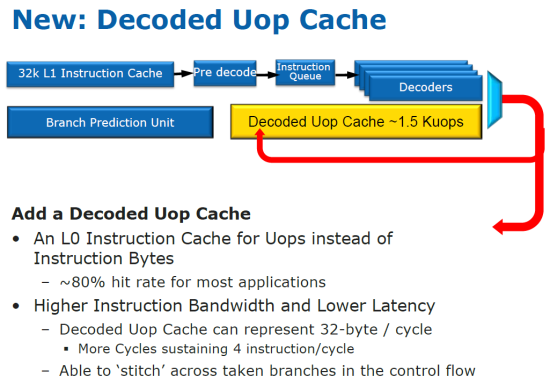
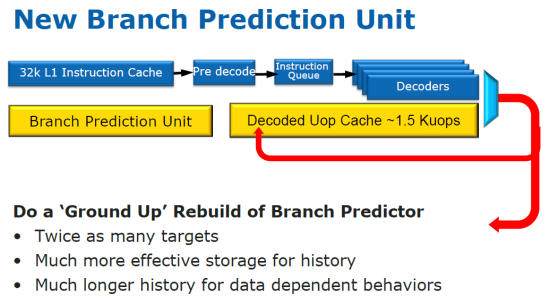
Výraznejšou zmenou prešiel aj blok predikcie vetvenia. Tento má teraz kompletne zrevidované buffery na ukladanie adries vetiev a histórie predikcie, čím sa do nich dá uložiť oveľa viac dát a teda aj hlbšia história. Podľa odhadov je na tomto mieste zlepšenie v predikcii asi o 5%. Neznie to síce ako veľa, no každá nesprávna predpoveď má za následok kompletné premazanie pipeline a jej nové naplnenie, čo stojí čas aj energiu.
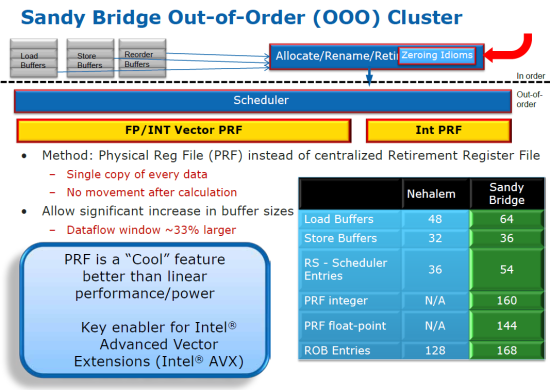
V Out-of-order klasteri sa opäť zaviedli PRF – Physical Register File. Predtým boli tieto odstránené v prvých Core a neskôr aj Nehalem procesoroch, u SandyBridge sa toto dedičstvo Pentium 4 vracia. V skratke ide o to, že v predošlých architektúrach sa preusporiadavali dekódované micro-ops a ukladali sa celé kópie registrov pre každý operand v bufferi. Teraz sa používajú iba odkazy na hodnoty registra uložené v PRF. Výhodou je zmenšenie presunu dát, ale aj zamedzenie duplikáciám a teda šetrenie priestorom v registroch.
Šetrenie presúvaných dát je namieste, pretože nové 256-bit inštrukcie by pri kopírovaní „hore-dole“ po čipe vytvárali veľa dodatočného toku a teda sa aj celý proces spomaľoval. AVX inštrukcie sú, dá sa povedať, ďalšou evolúciou SSE, ktoré rozširujú veľkosť SIMD vektorového registra na 256-bitov. Využiť sa budú dať na náročné floating-point výpočty v multimédiách, vedeckých či finančných aplikáciách. Intel ako príklad uvádza spájanie fotografií do panorám.

Exekučná jednotka bola upravená tak, aby sa 256-bit inštrukcie vykonávali efektívne. Hlavná zmena sa týka spojenia dvoch 128-bit exekučných jednotiek na spracovanie 256-bit dátových blokov.
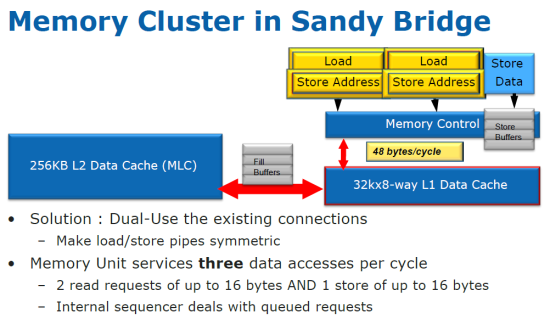
Z Nehalem-u sa presúvajú do Sandy Bridge aj tri porty určené na operácie Load, Store Adress a Store Data. Na zvýšenie ich efektívnosti sa rozhodlo, že dva z nich sa spoja a stanú sa rovnocenné. Dokážu nahrávať alebo ukladať adresy. Tretí port má nezmenenú funkciu – ukladá dáta. Každý port vie za jeden takt spracovať 16 bajtov, spolu je teda priepustnosť L1 dátovej cache zvýšená o 50%.
Celkový obrázok architekúry SandyBridge vyzerá potom nasledovne:
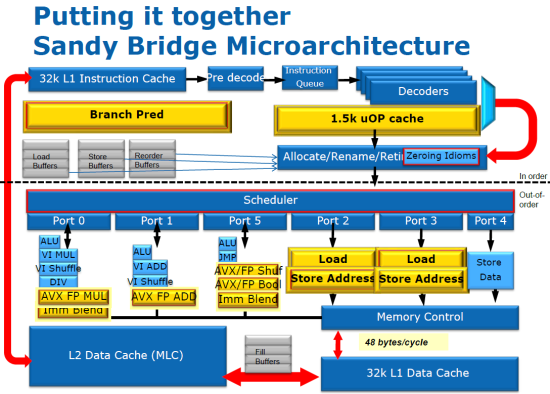
Pre viac detailných informácií odporúčam článok o architektúre na serveri RealWorldTech.com
lepermessiah
BurnerTom
intel32
PROMETHEUS
0Ro!
Tralalák
Gudas
jk2
nomisu
Gudas
bledos
Michal Kiradžiev
oliverr
Gudas
ace960
Gudas
ace960
bladejac